In my first semester of college I started learning about exploratory data analysis through a club. Web scraping and visualization interested me, so when I found the Ann Arbor Police and Division of Public Safety and Security had a website listing reports of crime each day , I decided I wanted to make that site my project.
Initially my scraper consisted of a for loop, an array, and a csv file. I quickly realized this was probably not the most efficient way to scrape thousands of reports from a clunky API, and I was constantly worried my array would run out memory and I would have to start all over.
I knew waiting for the API calls to return was slowing down the program so I tried adding multithreading to the for loop so that hopefully, more requests could run at once and the program runtime could be dramatically reduced. Quickly I realized I was in over my head. I was still barely holding onto async and suddenly I’m reading articles talking about registers and “the stack” and “the heap” when all I wanted to do was run more than 1 request at once. Eventually I pieced together something that looked s̵c̵a̵r̵y̵ good enough to me and seemed like it worked. This was that implementation.
The placebo effect worked well enough that I was content with my new fancy multithreaded scraping for the time being. I scraped in smaller batches and eventually had enough data gathered that I figured I could start analyzing the data. With a whole 6 weeks of pandas and matplotlib under my belt, I set off making graphs.
In the second semester I got bogged down with classes (and learned what the heap and stack were) so this project fell to the side. Come summer though, I started an internship where I needed to learn SQL. Because for some reason they wouldn’t let me learn SQL in the production environment, I saw the opportunity to dust off my old project, use the year of experience I had gained to improve it, and store the data in a SQL database instead of a couple of CSV’s.
I tried to set up a SQL server in AWS with a lot of frustration. After hour 3 of fighting with Amazon, I decided instead I would just run the server on my computer. Then after hour 3 of fighting with my computer, I decided I would check out this Azure thing Microsoft keeps telling me I should use. With the benefit of hindsight, getting the server running on my computer was very simple and quick, I just didn’t know what I was doing yet. Getting set up with Azure was mostly painless and after a few quick tutorials, I was up and running, scraping the DPSS site and storing crimes in my SQL table.
Again with the benefit of hindsight, the first thing I should have done was fix the multithreading. There is still room for improvement, but with my changes, the time to pull 10 days of data was reduced from approximately 79 seconds to 23 seconds.
In the future as I learn more statistical tests I want to try and extract more insight from this data set.
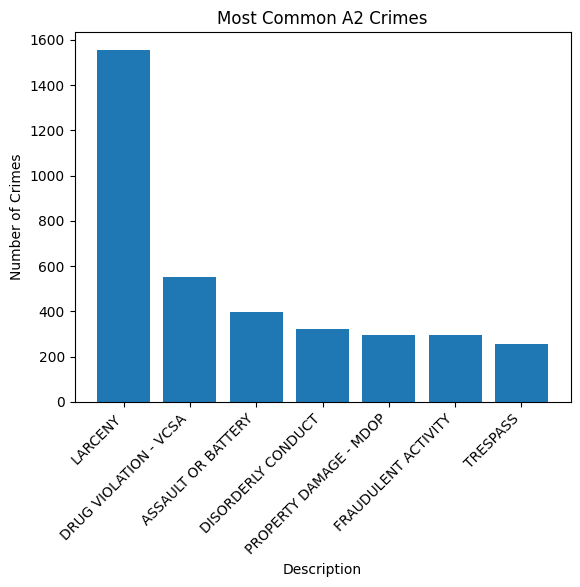
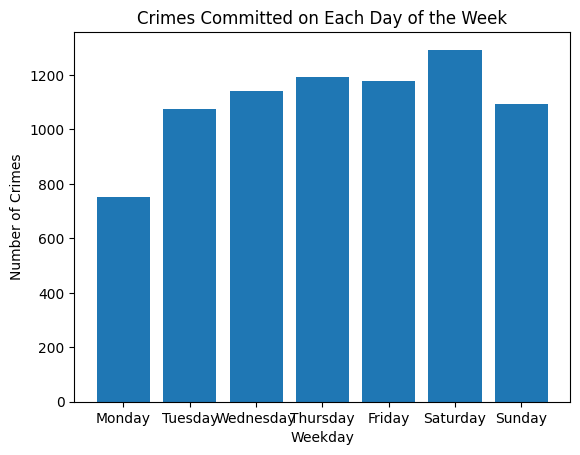
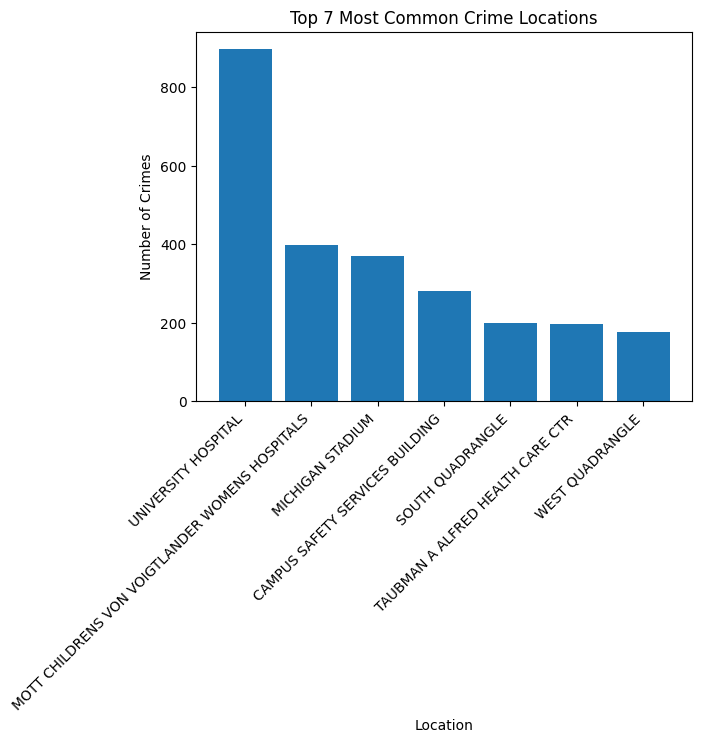
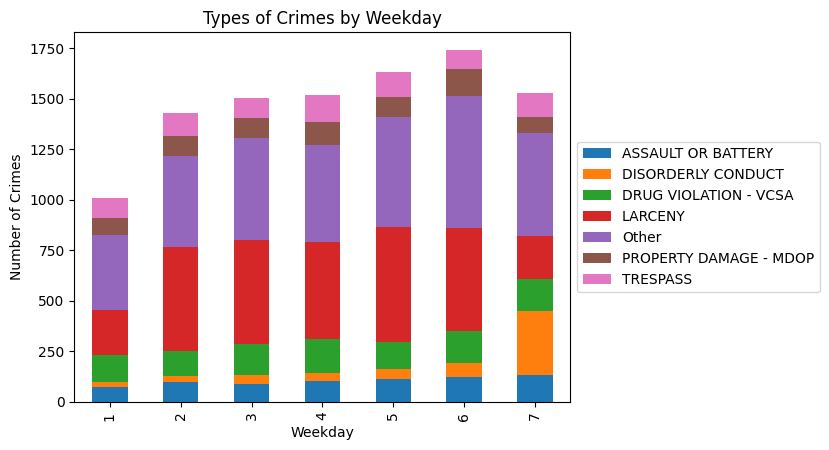
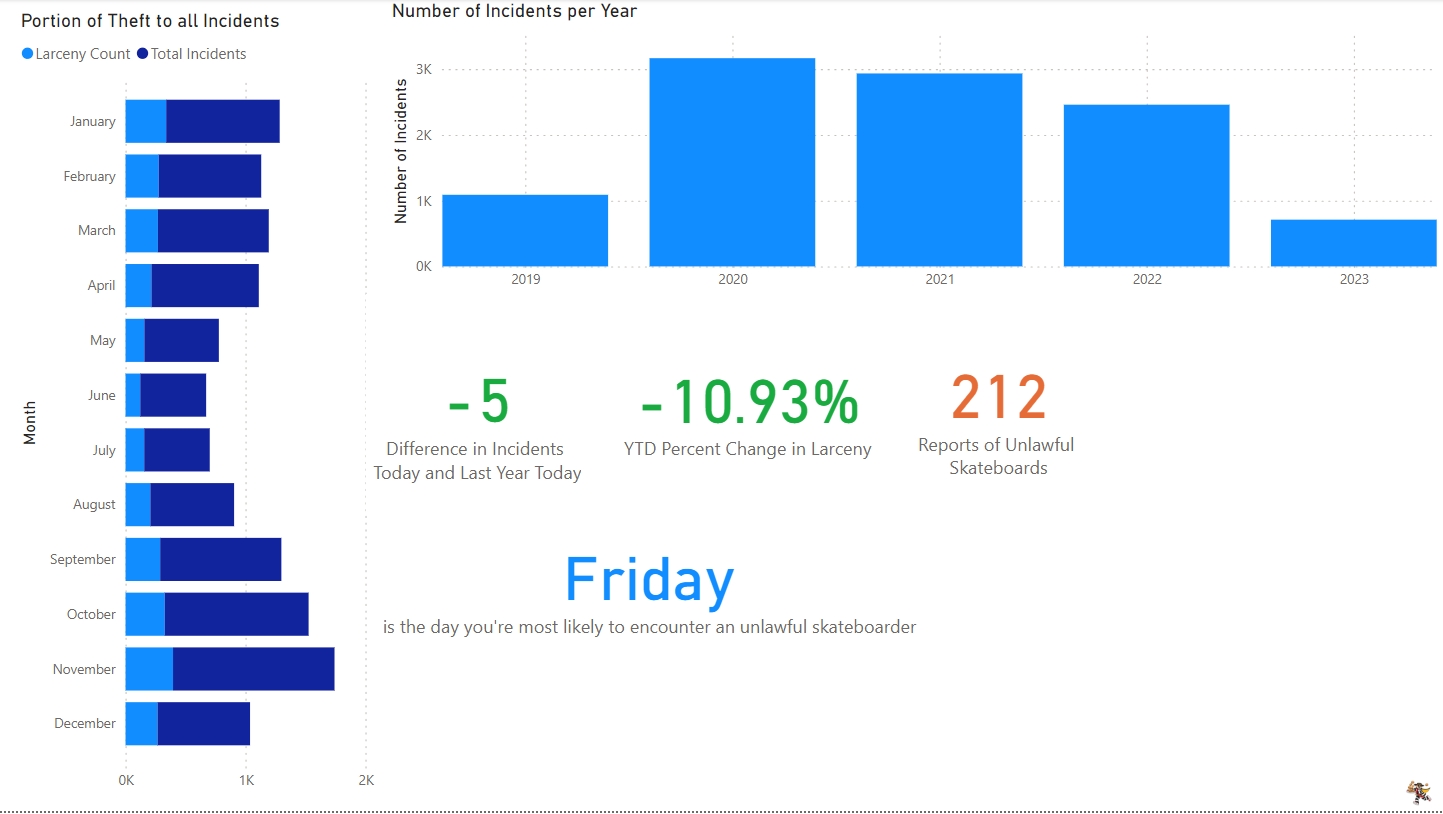
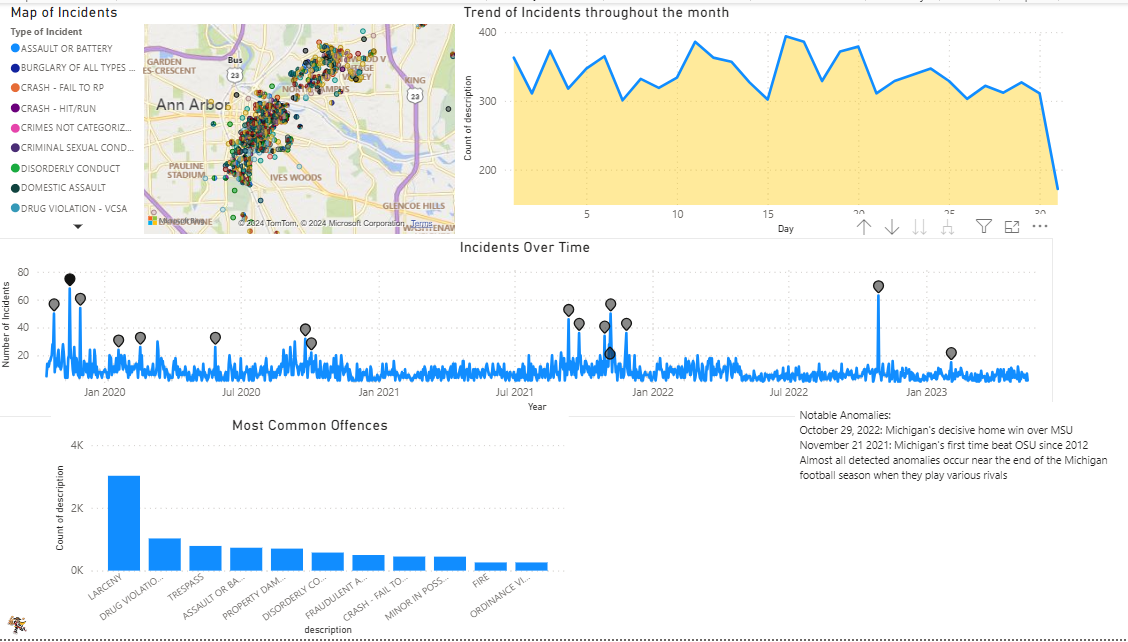
From a PowerBI dashboard I created